카카오의 모니터링 사례 조사
NEO - apm
naming
Neo from matrix

+Neo from kakao character

Neo 의 장점
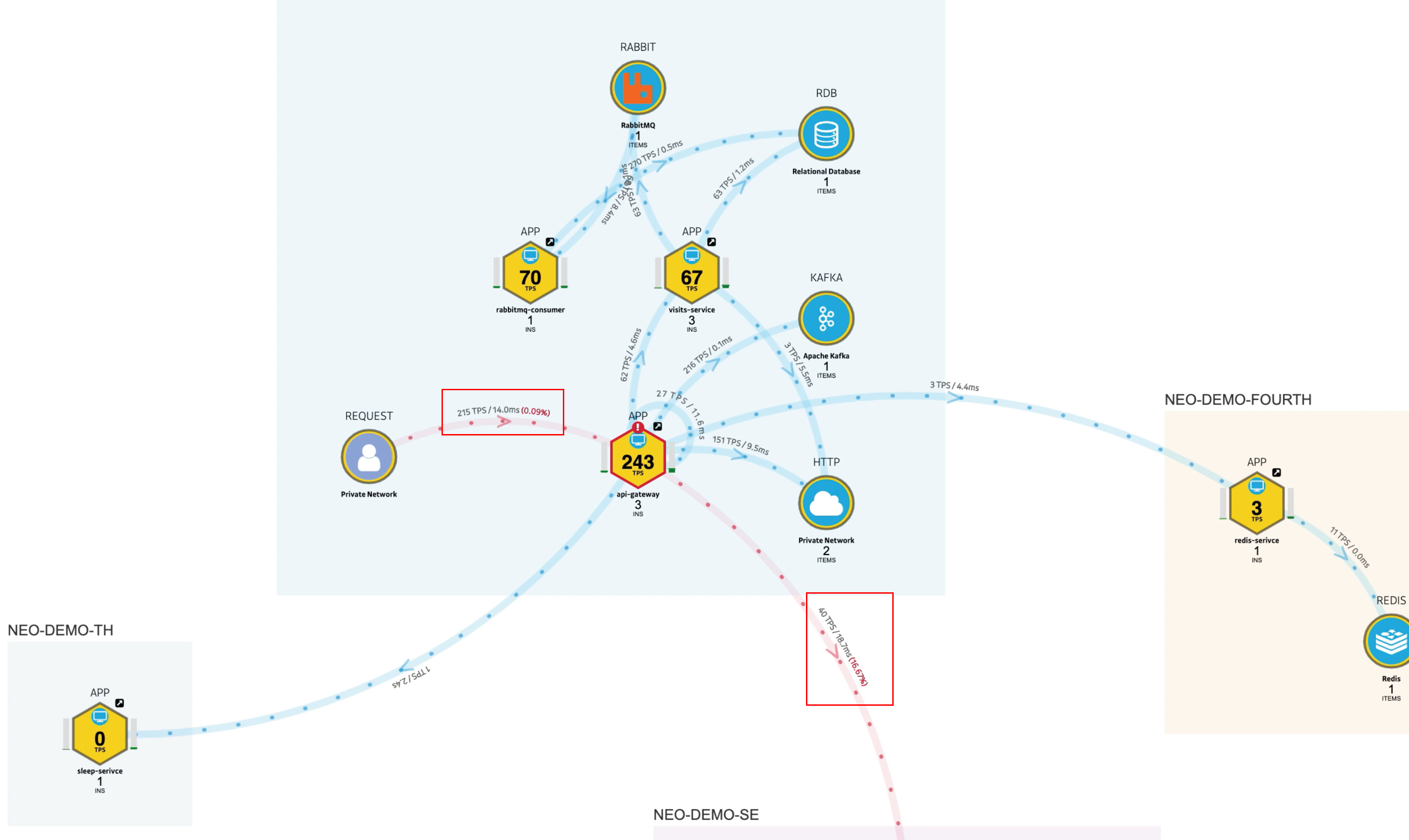
1. TPS/Response time(Error rate %) 이 나오는 Topology
- 215 TPS / Response time 14.0ms (Error rate 0.09%) 의 정보가 Topology 화면에 효과적으로 표시 됩니다.
- Service Grouping 도 지원하는 것으로 추정합니다.
2. Observability
- 요새 모니터링의 트렌드인 Observability(관측가능성)를 강화하기 위해, x-view 에서 daily compare 를 지원합니다.
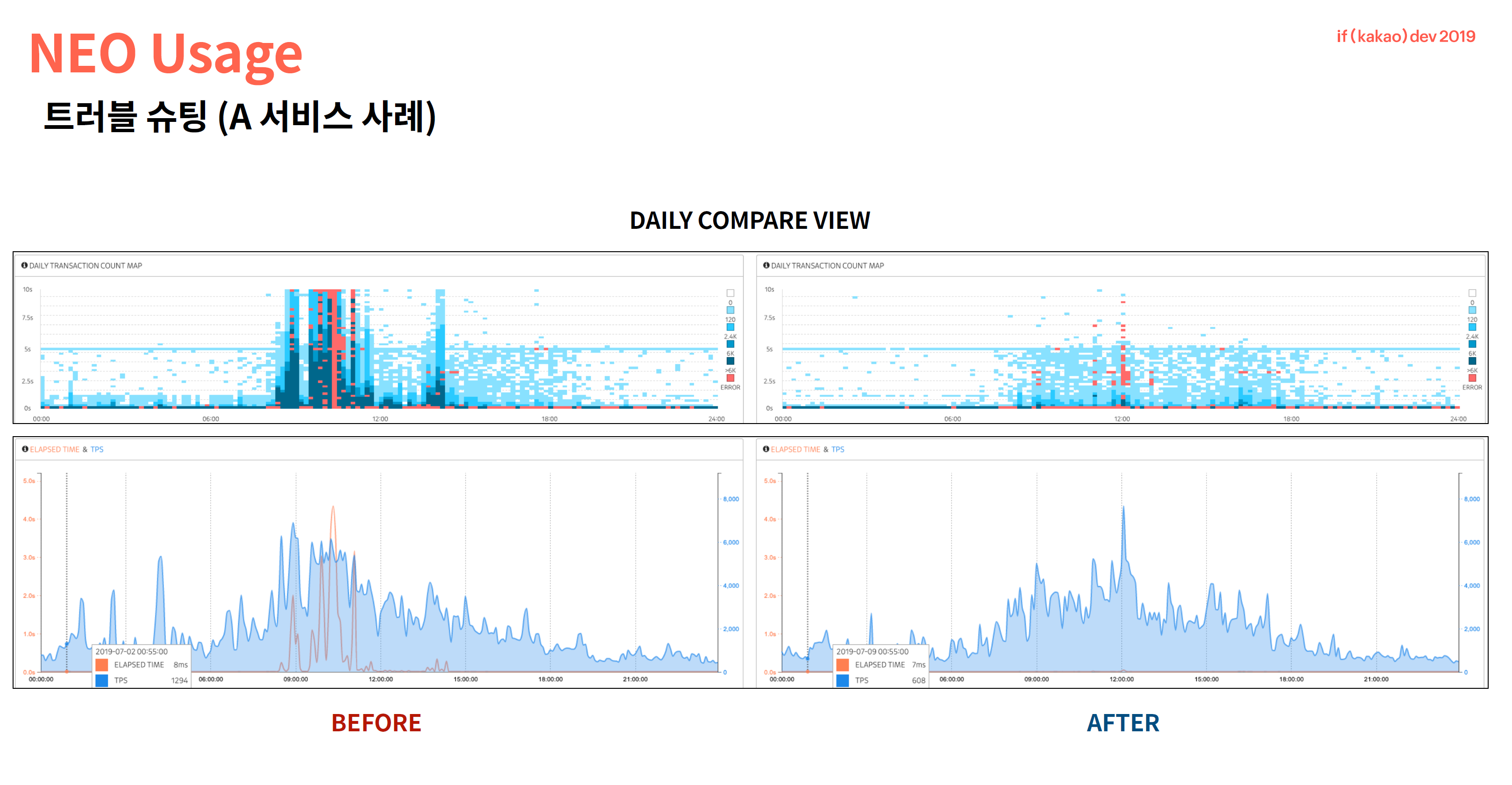
Observability is the ability to infer internal states of a system based on the system’s external outputs. In control theory, observability is a mathematical dual (follows a direct conceptual mapping) to controllability, which is the ability to control internal states of a system by manipulating external inputs.
; output log 로부터 시스템 내부의 상태를 유추. 단순한 데이터의 나열이 아닌, 변화를 인식할 수 있는 의미있는 추론
3. Adaptive Sampling
- 응답시간별 샘플링 : agent 에서 response time 이 빠른 건은 적게 샘플링하고, response time 이 느린건은 많이 샘플링 합니다.
- 예상컨데, Application 에서는 interceptor 가 100% 실행되고, agent -> collector 로 보낼때 sampling 이 적용되는 것으로 추정합니다. cpu 는 희생하고, network 부하 감소를 위한 sampling 방법으로 추정합니다.
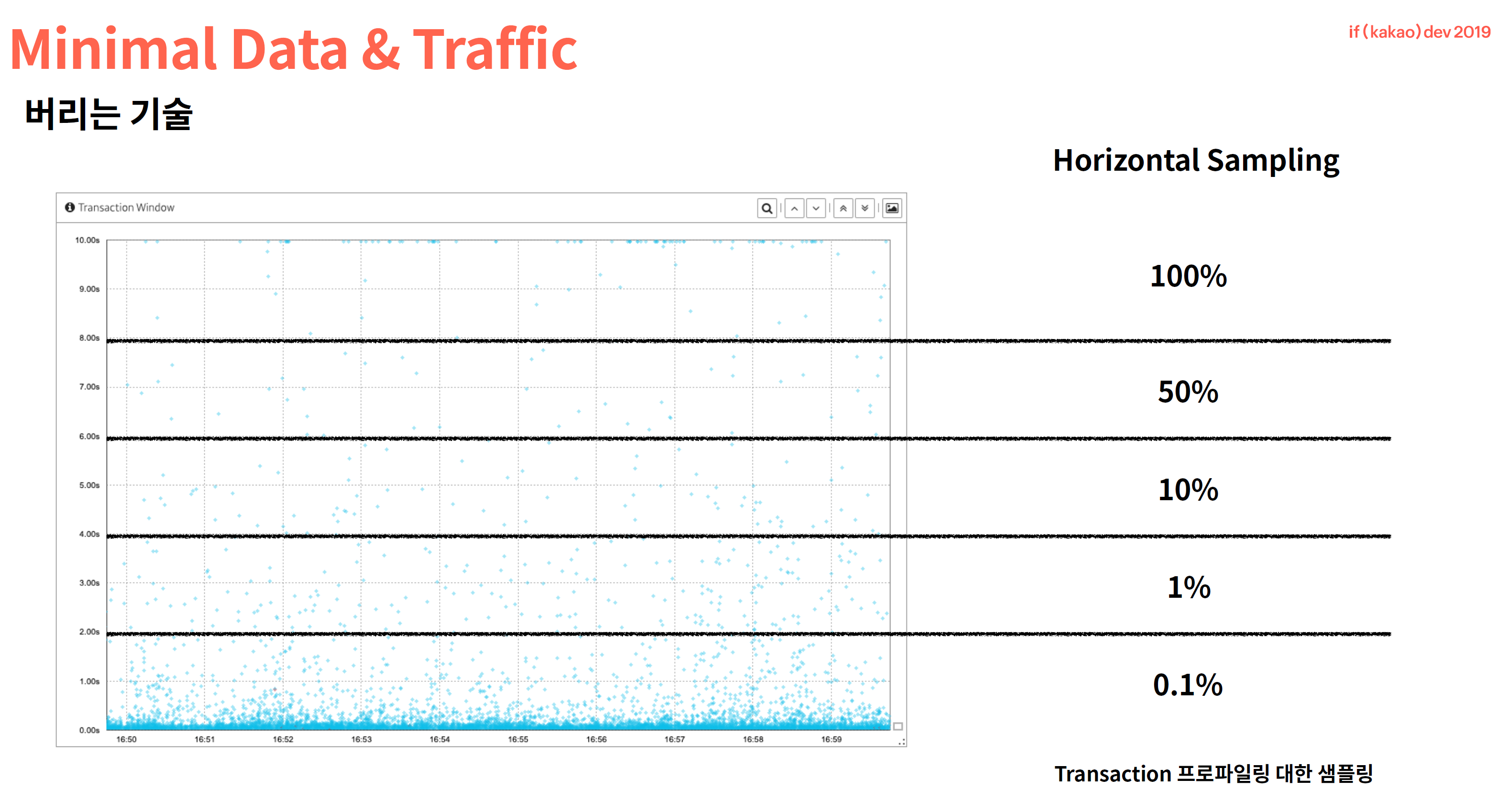
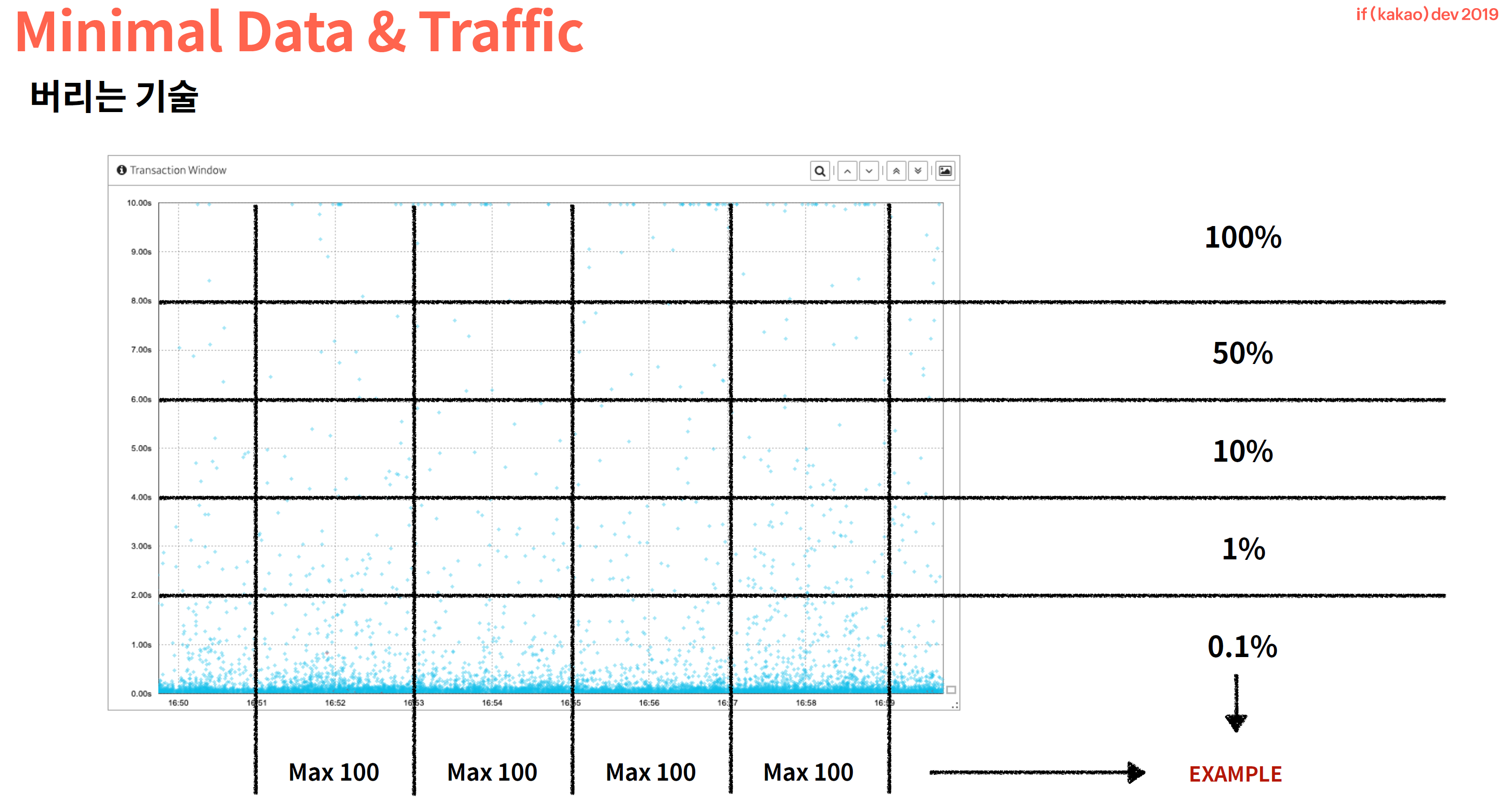
- vertical sampling 은 window 기법으로 특정 시간대만 sampling 하는 방법을 사용한 듯 합니다. 위의 응답시간별 샘플링은 network 부하를 경감하기 위한 방법이라면, vertical sampling 은 cpu/memory 부하를 경감하기 위한 sampling 으로 보입니다. 순서상으로는
- 1.vertical sampling ( 시간별, cpu/memory 부하경감 ) 이 먼저 진행되고
- 2.horizontal sampling ( 응답시간별, network 부하경감 ) 이 나중에 진행되리라
추정합니다만 응답시간별 샘플링은 kakao 가 처음 시도하는 것이여서 강조하기 위해 먼저 소개한 것 같습니다.
- Traffic limit 과 Backpressure(queue?) 를 지원합니다.
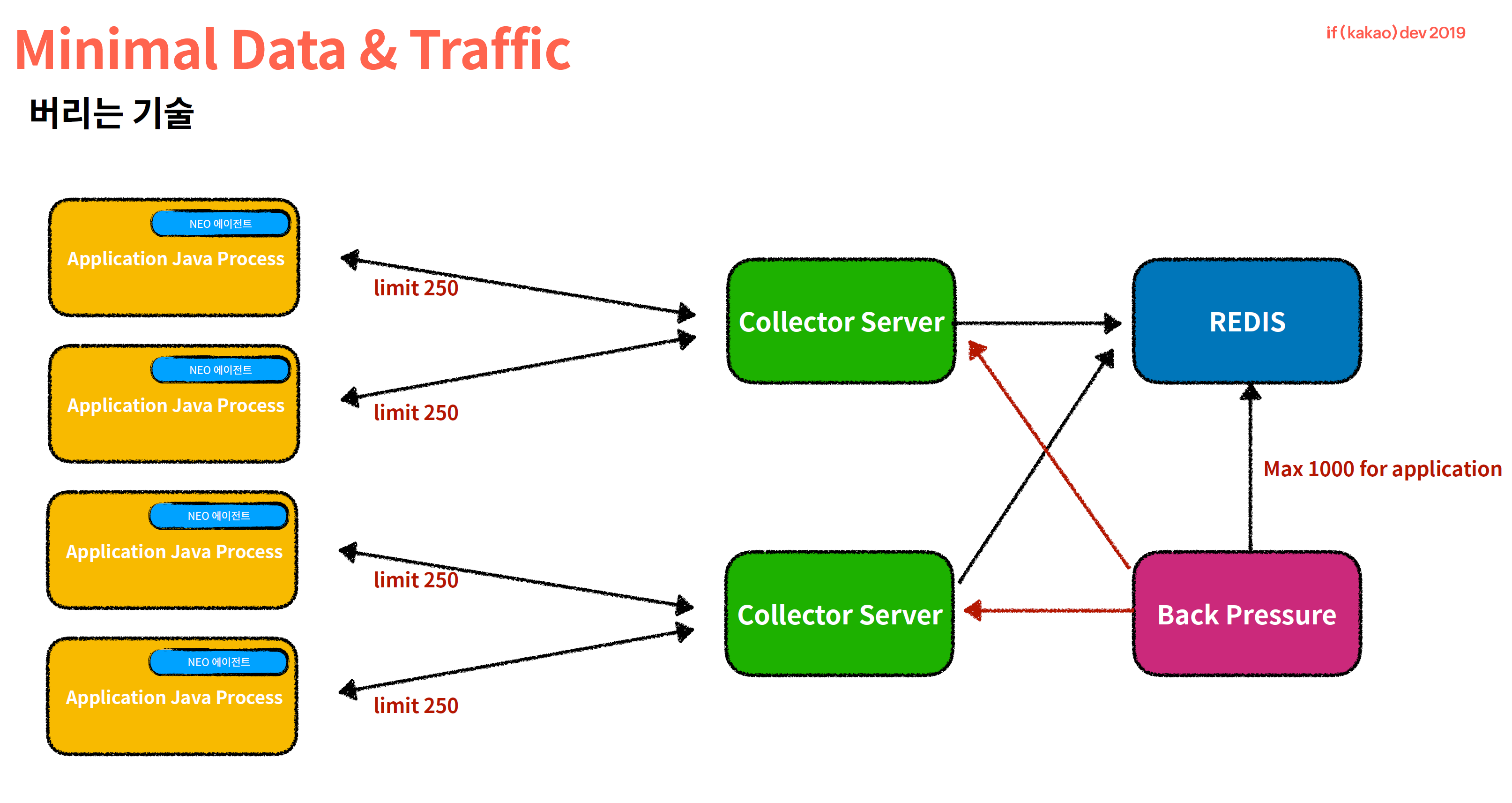
feature
Main dashboard
많은 사람들이 좋아하는 X-view 를 지원합니다. 함께 볼 수 있는 지표는 아래의 표와 같습니다.
| Transaction Window(X-view) | Active Transaction | Response Time |
|---|---|---|
| Transaction Window(X-view) | Visitor Count | TPS |
| CPU(node) | Process Cpu(pod) | Memory | Used Heap |
|---|---|---|---|
| Service count | Active Count | Error Rate | Open FileDescriptor |
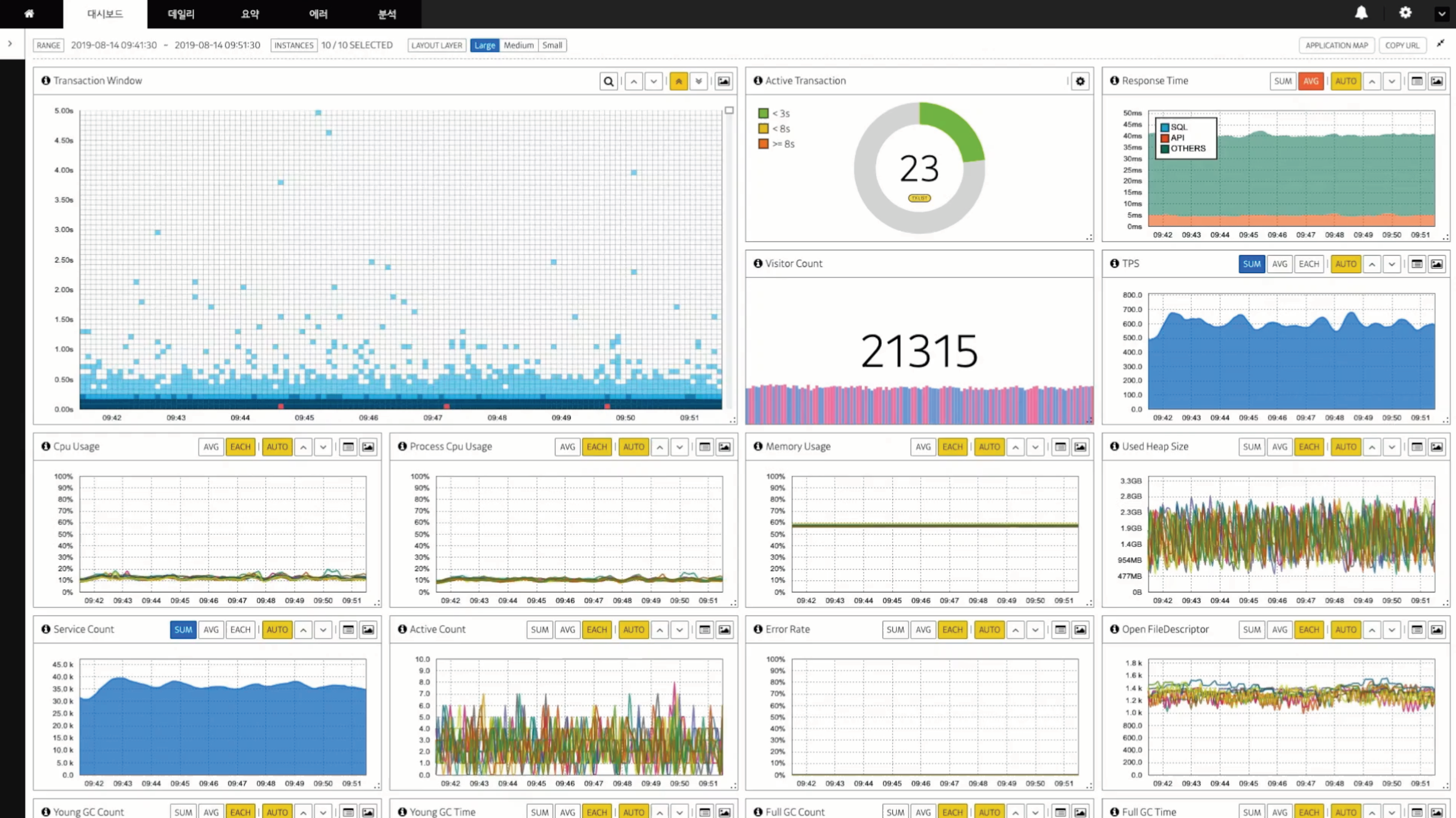
Spec & Data
- Yesterday Message Size : 1.1 TiB
- Yesterday Message Count : 89억 ( 10만/s )
- Cassandra
- tsp : 13만/s
- db spec server 사용 ( 발표하신 김은수님이 당시, 자세한 spec 은 모르셨어요 )
- idc 당 5대 * 2 = 10대
- memory 64G 중 50% JVM
Cassandra
- High performance writing
- WRITE > read
- Scalibility
- idc 지원 -> dc=pg|gs, pg 판교, gs 가산
- idc 지원 -> dc=pg|gs, pg 판교, gs 가산
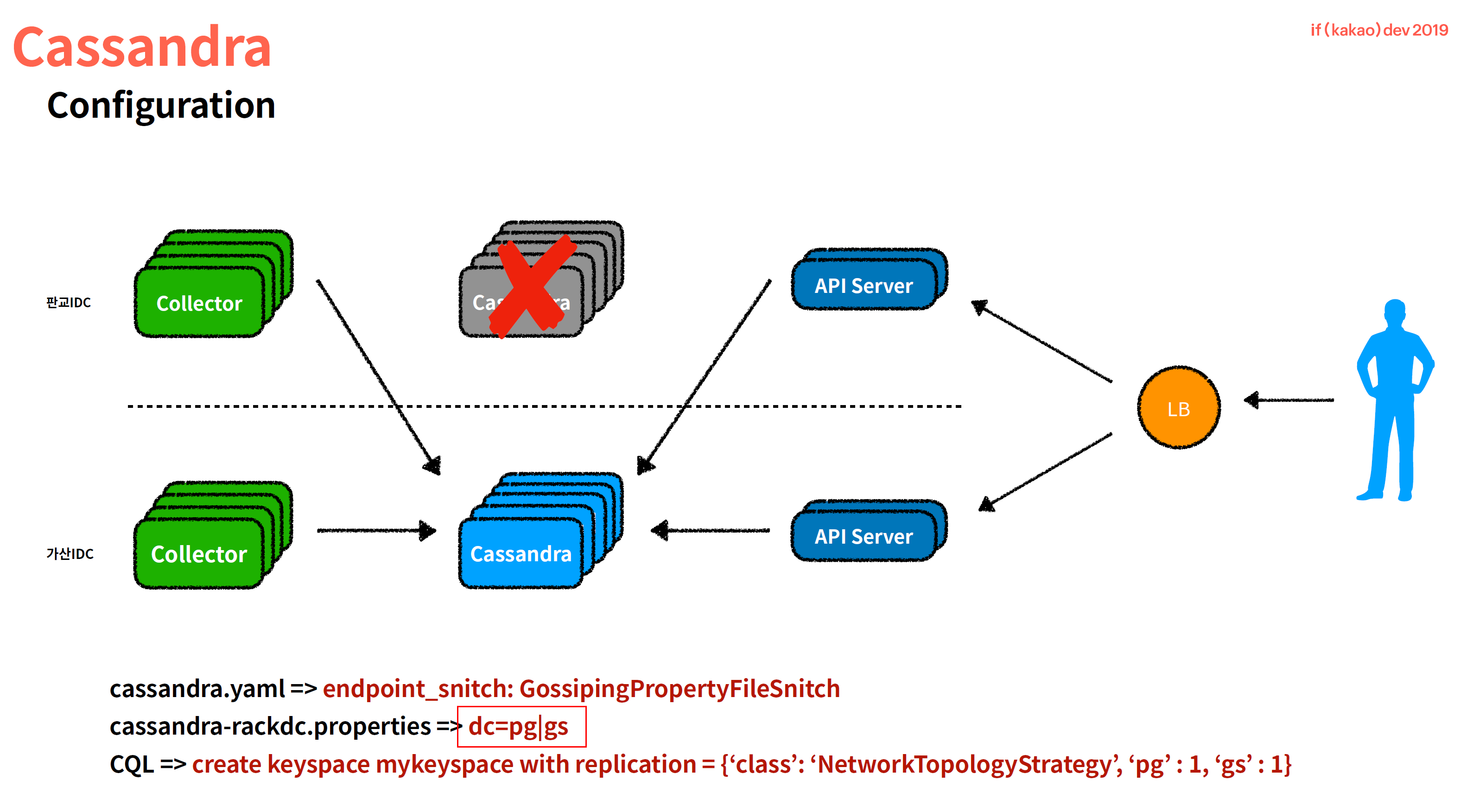
- Time series data store
- partition key : 어느 파티션으로 -> Application ID + Time Bucket
- cluster key : 어느 순서로 -> Time
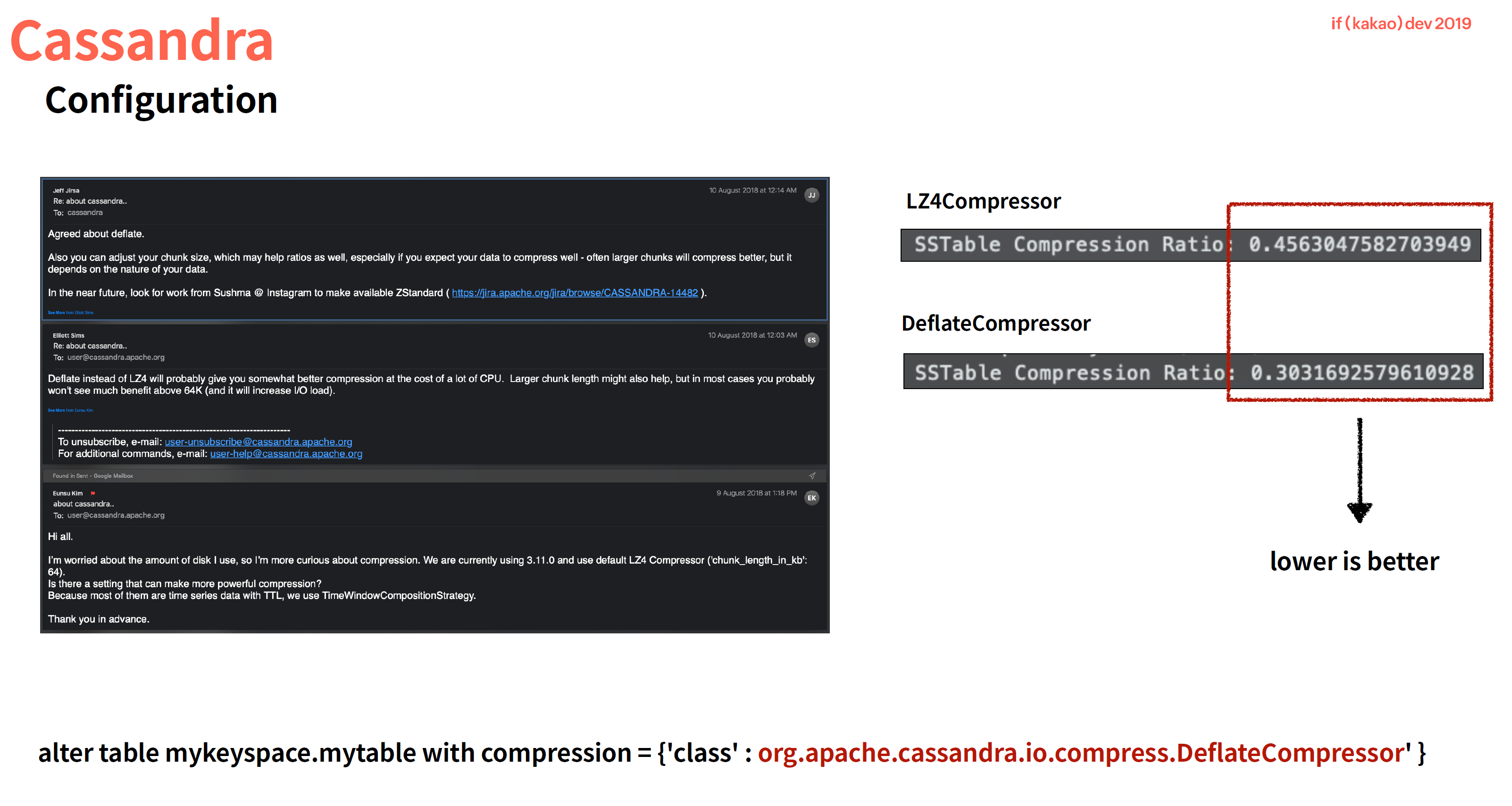
- 장애경험 공유 : LZ4Compressor 가 Disk IO 를 많이 먹어서, DeflateCompressor 를 사용
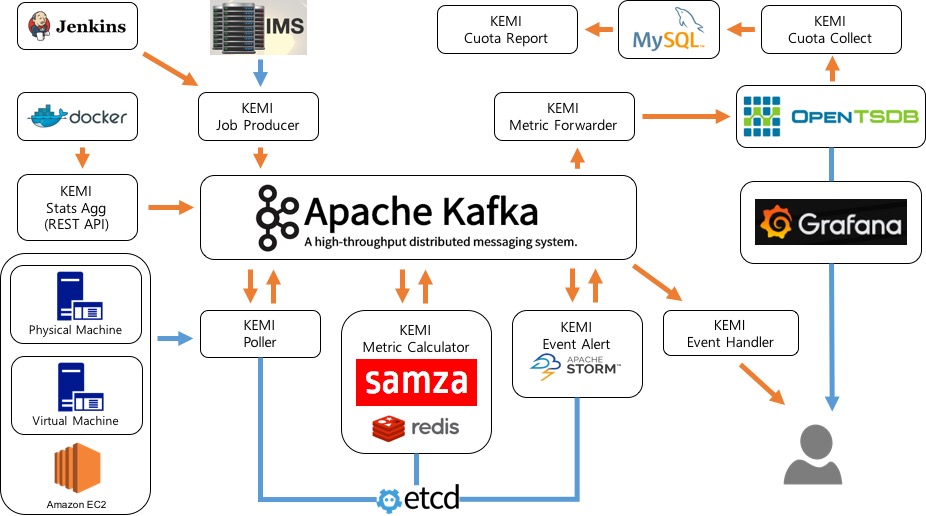
KEMI - efk
NEO 에서 너무 많은 시간을 사용해서, KEMI 쪽은 나중에 다시 정리해야 되겠습니다.
KEMI-Stat
KEMI-Log
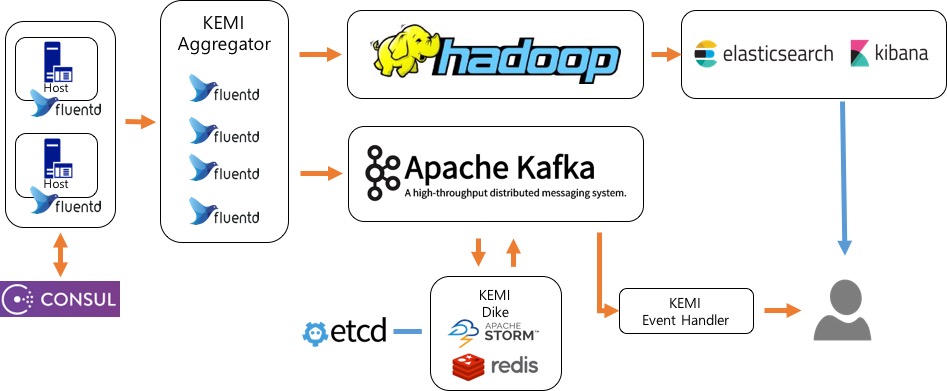
- EFK Elasticsearch + Fluentd + Kibana
PostgreSQL : JSON
- json 을 text 로 저장
PostgreSQL : JSONB
- key-value 형태의 binary로 저장
- indexing 지원 ( B-Tree, GIN )
Reference
KEMI efk
KEMI(Kakao Event Metering & monItoring) tech blog 2016
Microservice에서 쏟아지는 로그를 Perl5를 사용하여 로그수집기들로 잘 보내고 활용하기 pdf 2019
Microservice에서 쏟아지는 로그를 Perl5를 사용하여 로그수집기들로 잘 보내고 활용하기 mp4 2019
NEO apm
카카오 애플리케이션 모니터링 NEO apm pdf 2019
카카오 애플리케이션 모니터링 NEO apm mp4 2019